⚙️ Optimization
Model Optimization
ลดขนาดโมเดลและเพิ่มความเร็ว — Quantization, Pruning, Distillation
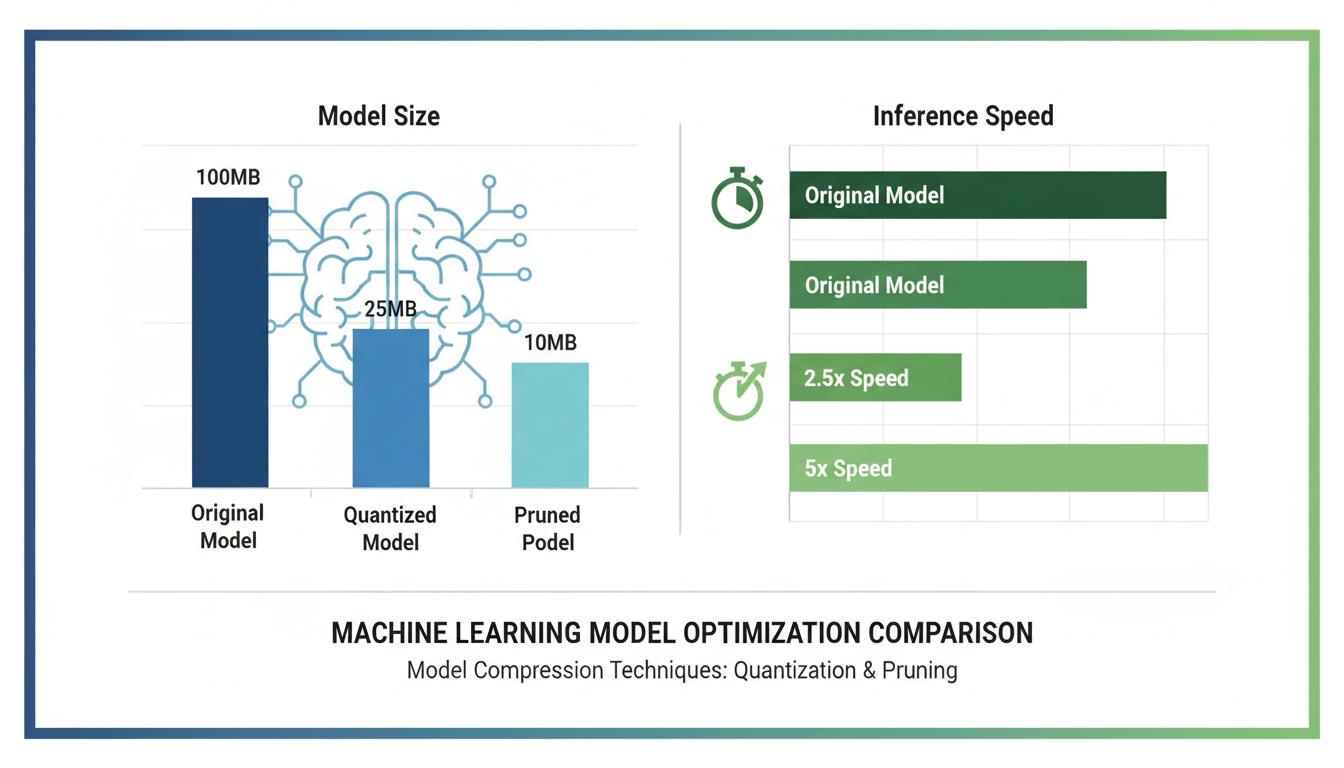
4X
เร็วขึ้น
75%
ลดขนาด
<1%
Accuracy Loss
คุณสมบัติหลัก
จุดเด่นของเทคโนโลยีนี้
Quantization
แปลง FP32 เป็น INT8 ลดขนาดและเพิ่มความเร็ว
Pruning
ตัด weight ที่ไม่จำเป็นออกจากโมเดล
Knowledge Distillation
ถ่ายทอดความรู้จากโมเดลใหญ่ไปยังโมเดลเล็ก
TensorRT
ใช้ NVIDIA TensorRT เร่งความเร็ว inference
ONNX Export
แปลงโมเดลเป็น ONNX สำหรับ cross-platform deployment
Module Fusion
รวม layer เพื่อลด overhead ในการ inference
ประโยชน์
ทำไมคุณถึงต้องการเทคโนโลยีนี้
Deploy บน Edge ได้
ลดขนาดโมเดลให้ทำงานบน Jetson, Raspberry Pi
เร็วขึ้น 4 เท่า
Inference เร็วขึ้นมากโดย accuracy แทบไม่ลด
ลดค่า hardware
ใช้ GPU ขนาดเล็กลง ประหยัดต้นทุน
ลดพลังงาน
โมเดลที่เล็กลงใช้พลังงานน้อยกว่า
เทคโนโลยีที่เกี่ยวข้อง
สำรวจเทคโนโลยีเพิ่มเติม
เนื้อหาที่เกี่ยวข้อง
ค้นพบเพิ่มเติม
หัวข้อที่เกี่ยวข้อง
พร้อมนำเทคโนโลยี AI มาใช้?
ปรึกษาผู้เชี่ยวชาญของเราวันนี้ — ฟรีไม่มีค่าใช้จ่าย