⚡ Transformers
Transformer Models สำหรับ Vision
สถาปัตยกรรม Attention ที่กำลังเปลี่ยนวงการ Computer Vision — จาก ViT ถึง DETR
SOTA
ผลลัพธ์
1B+
พารามิเตอร์
2020+
ยุค Vision Transformer
คุณสมบัติหลัก
จุดเด่นของเทคโนโลยีนี้
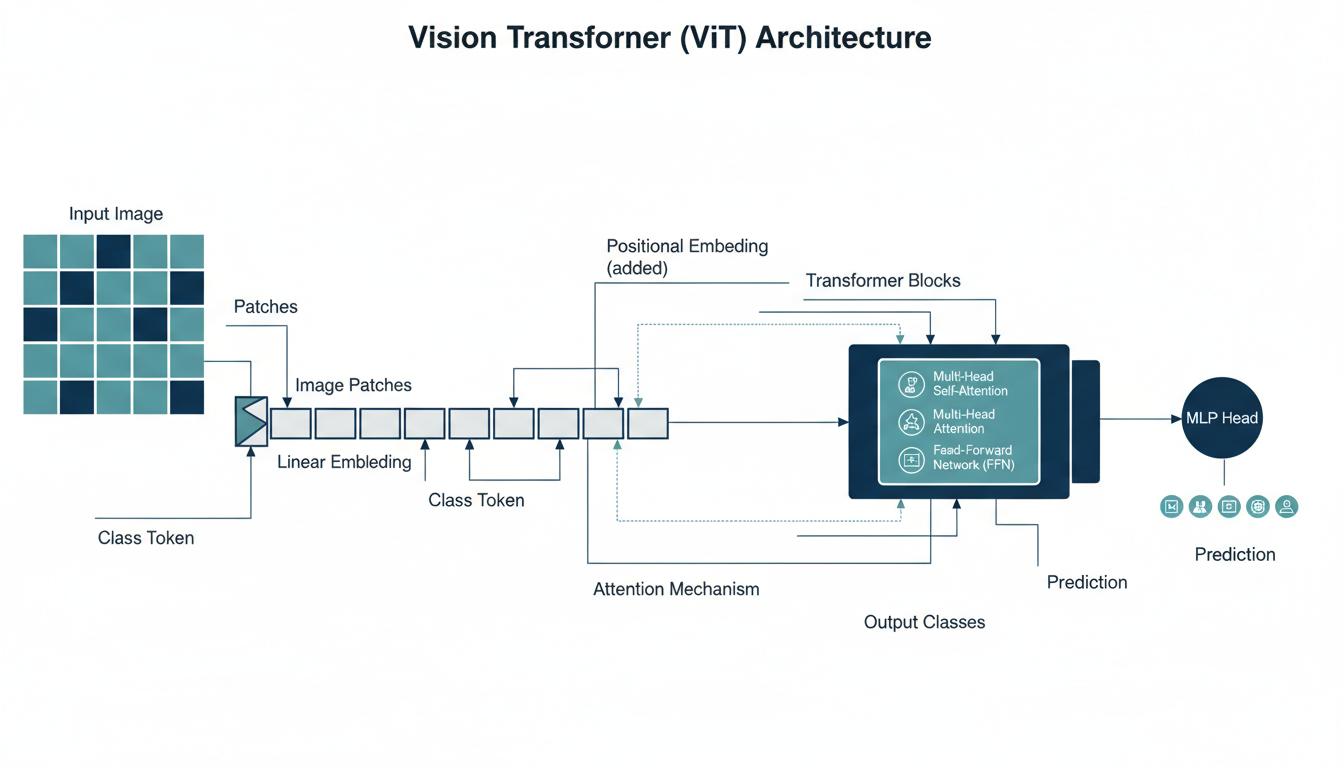
Vision Transformer (ViT)
ใช้ patch embedding แทน convolution สำหรับจำแนกภาพ
DETR
Detection Transformer — ตรวจจับวัตถุโดยไม่ต้องใช้ anchor
Swin Transformer
Hierarchical vision transformer สำหรับ dense prediction
Self-Attention
กลไก attention ที่เข้าใจความสัมพันธ์ระหว่างส่วนต่างๆ ของภาพ
Foundation Models
โมเดลขนาดใหญ่ที่ฝึกจากข้อมูลมหาศาล เช่น CLIP, SAM
Multi-Modal
เชื่อมภาพกับภาษาธรรมชาติ เช่น CLIP, GPT-4V
ประโยชน์
ทำไมคุณถึงต้องการเทคโนโลยีนี้
ผลลัพธ์เหนือ CNN
ทำคะแนน SOTA ในหลาย benchmark ด้าน vision
เข้าใจ Global Context
Self-attention มองเห็นความสัมพันธ์ทั่วทั้งภาพ
ทำงานร่วมกับภาษา
ใช้ prompt ภาษาธรรมชาติควบคุม vision task ได้
Foundation Model Era
เป็นพื้นฐานของ AI ยุคใหม่ที่ทำได้หลายอย่าง
เทคโนโลยีที่เกี่ยวข้อง
สำรวจเทคโนโลยีเพิ่มเติม
เนื้อหาที่เกี่ยวข้อง
ค้นพบเพิ่มเติม
หัวข้อที่เกี่ยวข้อง
พร้อมนำเทคโนโลยี AI มาใช้?
ปรึกษาผู้เชี่ยวชาญของเราวันนี้ — ฟรีไม่มีค่าใช้จ่าย