⚙️ Optimization
Model Optimization
Shrink models and boost speed — quantization, pruning, and distillation
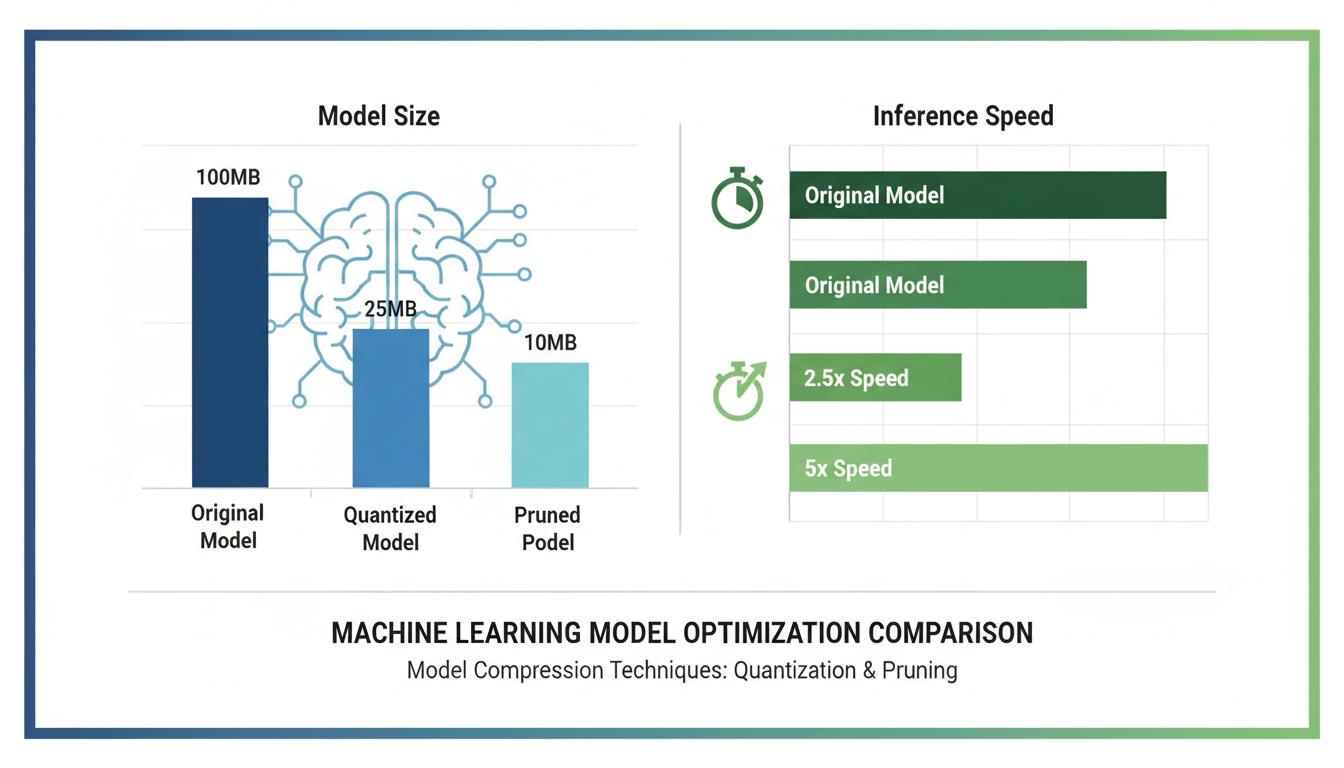
4X
Speedup
75%
Size Reduction
<1%
Accuracy Loss
Key Features
What Makes This Technology Special
Quantization
Convert FP32 to INT8 for smaller size and faster inference
Pruning
Remove unnecessary weights from the model
Knowledge Distillation
Transfer knowledge from large teacher to small student model
TensorRT
Accelerate inference with NVIDIA TensorRT
ONNX Export
Convert models to ONNX for cross-platform deployment
Module Fusion
Merge layers to reduce inference overhead
Benefits
Why You Need This Technology
Deploy on Edge
Shrink models to run on Jetson, Raspberry Pi
4X Faster
Much faster inference with minimal accuracy loss
Lower Hardware Costs
Use smaller GPUs — save on hardware investment
Lower Power Usage
Smaller models consume less energy
Related Technologies
Explore More Technologies
Related Content
Discover More
Explore Related Topics
Ready to Deploy AI Technology?
Consult with our experts today — free of charge