🗣️ Vision-Language
Vision-Language Models
โมเดล AI ที่เข้าใจทั้งภาพและภาษา — ใช้ prompt ภาษาธรรมชาติสั่งงาน Computer Vision
CLIP
Foundation
GPT-4V
Multi-Modal
Zero-shot
ไม่ต้องฝึก
คุณสมบัติหลัก
จุดเด่นของเทคโนโลยีนี้
CLIP
เชื่อมภาพกับข้อความ เข้าใจความสัมพันธ์ระหว่างทั้งสอง
GPT-4V / Gemini
Multi-modal LLM ที่เข้าใจภาพและตอบคำถามได้
Zero-Shot Classification
จำแนกภาพโดยไม่ต้องฝึกสอน — แค่บอกชื่อ class
Image Captioning
อธิบายภาพด้วยภาษาธรรมชาติอัตโนมัติ
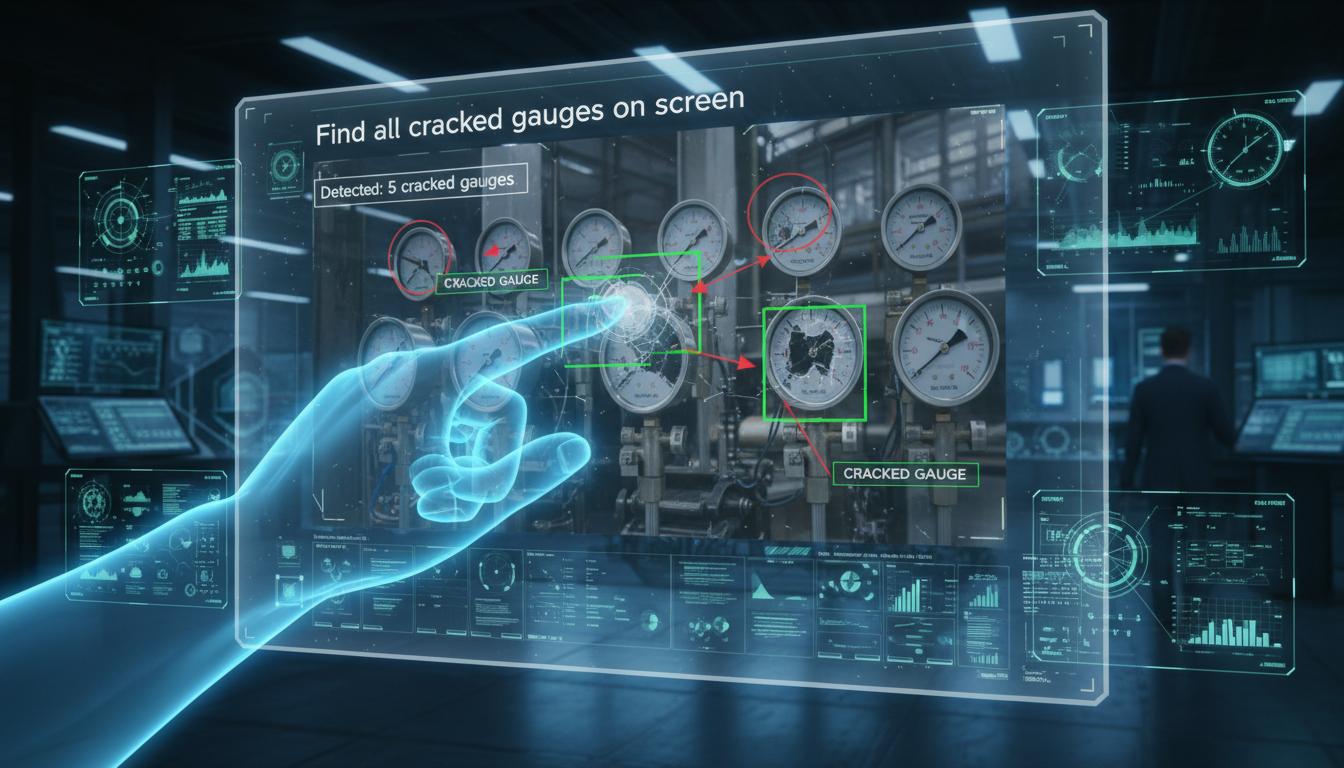
Visual QA
ถามคำถามเกี่ยวกับภาพแล้วได้คำตอบ
Text-to-Image
สร้างภาพจากคำอธิบายภาษาธรรมชาติ เช่น DALL·E
ประโยชน์
ทำไมคุณถึงต้องการเทคโนโลยีนี้
ไม่ต้องฝึกสอนใหม่
ใช้ Zero-shot จำแนกภาพใหม่ได้ทันที
สั่งงานด้วยภาษาคน
ใช้ prompt ภาษาธรรมชาติแทนการเขียนโค้ด
เข้าใจ context
เข้าใจบริบทของภาพ ไม่ใช่แค่จำแนกวัตถุ
อนาคตของ AI Vision
เทรนด์ที่จะเปลี่ยนวิธีการใช้ AI ในอุตสาหกรรม
เทคโนโลยีที่เกี่ยวข้อง
สำรวจเทคโนโลยีเพิ่มเติม
เนื้อหาที่เกี่ยวข้อง
ค้นพบเพิ่มเติม
หัวข้อที่เกี่ยวข้อง
พร้อมนำเทคโนโลยี AI มาใช้?
ปรึกษาผู้เชี่ยวชาญของเราวันนี้ — ฟรีไม่มีค่าใช้จ่าย